Automating NZ Wireless Map with Google Cloud Run
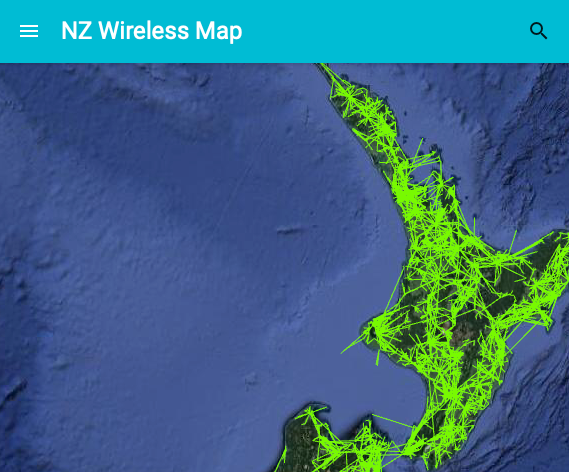
Almost a year ago, I promised a post detailing how I process NZ Wireless Map's data to keep it fresh. Here it is:
Recap: The Problem
NZ Wireless Map is a map of the point-to-point wireless links in New Zealand, using data pulled from the NZ spectrum regulator, who host a weekly Microsoft Access data dump on their website.
At a high-level, I wanted:
- Low-latency: new data dumps from Radio Spectrum Management should be reflected in NZ Wireless Map within the day.
- Low-maintenance: the data pipeline should run itself, I shouldn't have to log in and run manual steps.
- Cheap: This is a hobby project, I don't want to spend more than a dollar a month on it.
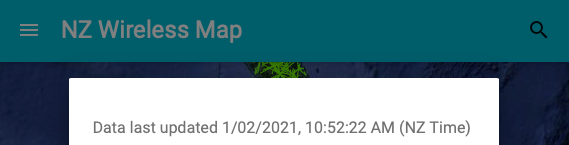
- An auto-updating indicator on the NZ Wireless Map site of how stale the data is: when the last fetch was. This is transparent for users and makes it clear if the site stops updating.
I also wanted it to be cheap: This is a hobby project, I don't want to spend more than a dollar a month on it.
- So I don't want to recompute data (and pay for it) every day if it's only changed once a week.
- I also want to be nice to the Radio Spectrum Management web host, so they don't block me. This means caching the fetched results, rather than re-fetching every time.
I read the links from this Microsoft Access database, converting the database to SQLite3 (because I don't have Microsoft Access), exporting raw links to CSV, converting to JSON, and uploading to the NZ Wireless Map site.
Radio Spectrum Management Website
↓ fetch over HTTP
Microsoft Access Database File
↓ convert (using Java)
SQLite3 Database
↓ query with SQL
CSV Point-to-point links
↓ convert
JSON Point-to-point links
↓ upload
NZ Wireless Map Site (Google Cloud Storage)This was historically difficult to tie together on a hosted platform, because hosted platforms often force you to use a single language. With so many different technologies (Java, Microsoft Access, and SQLite (C code), Google Cloud). Many function-as-a-service runtimes require that they compile your code, which prevents you from bundling native libraries or combining Java code with Go.
Enter Google Cloud Run
Disclaimer: I work at Google, but not on their Cloud team.
Google Cloud Run hosts your code, with pay-by-the-second compute pipelines. Cloud Run runs code in whatever language you want, as long as the code can respond to an HTTP request from inside a Docker image. This opens up opportunities to cheaply run code written in many languages.
Cloud Run takes your Docker container image, starts the container whenever there's an incoming request, and immediately scales back down to zero compute usage after the request is finished. You only pay for the seconds of compute you use. Cloud Run takes care of scheduling on machines; all you have to specify is a region and a size of machine. You don't have to run an always-on Kubernetes fleet. And there's even a generous free tier. This makes it a really cheap, attractive option for budget-conscious apps that don't need to always be running.
But how do you run the container on a schedule? Google Cloud Scheduler is a hosted Cloud cron that sends HTTP requests on a schedule.
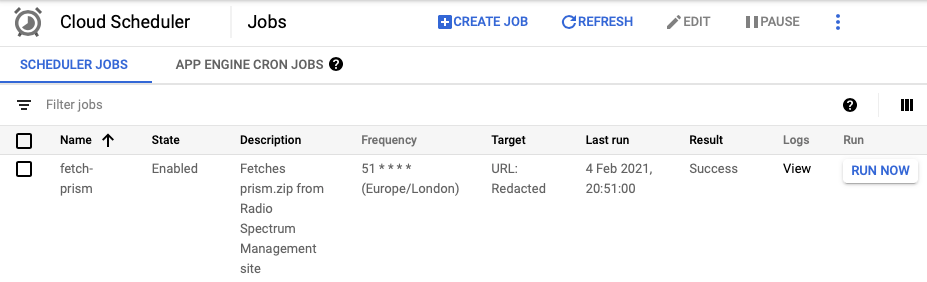
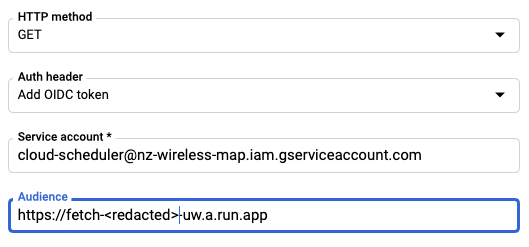
I faced some difficulties plugging Cloud Scheduler into Cloud Run, particularly around authentication. Cloud Run kept rejecting Cloud Scheduler's HTTP requests as authorised, despite coming from inside the same project. The docs could be clearer here, it was pretty unclear how to setup auth.
I got it working by selecting "Add OIDC token" with a service account cloud-scheduler@nz-wireless-map.iam.gserviceaccount.com, and "Audience" of the URL of my Cloud Run service: https://fetch-<redacted string>-uw.a.run.app.
So, to recap, we have:
- A way to trigger HTTP requests on a schedule
- A way to launch a docker container from an HTTP request
- Some confidence that I can bundle this data pipeline into a Docker container.
Solution
- Poll Radio Spectrum Management's website on a schedule, checking if the data has changed since I last processed data successfully. Exit early if I've already processed the latest database. I hope this will ensure that if a pipeline transiently fails, it will be retried and hopefully succeed next time without me having to manually intervene.
- Fetch the .zip, cache the .zip in an immutable timestamped file on Cloud Storage (for debugging and possibly rolling back)
- Unzip the .zip, convert the Microsoft Access File inside to SQLite
- Execute a SQLite query on the SQLite database, outputting CSV. Cache the CSV in an immutable timestamped file on Cloud Storage (for debugging)
- Convert the CSV to JSON, for fast client-side parsing. Push this to an immutable timestamped file on Cloud Storage (for easy rollbacks), and to a
latest.jsonfile which the NZ Wireless Map web UI will load.
The Pipeline Dockerfile
First, put Java and SQLite and Python onto the server. Start from the no-nonsense, tiny alpine Linux distribution, and add the bare necessities: language runtimes, and TLS root certificates, essential for making HTTPS requests.
# Dockerfile
FROM alpine:3
RUN apk add --no-cache ca-certificates openjdk8-jre sqlite python3Include the Java mdb-sqlite.jar converter into the container, and the SQL script for extracting point-to-point into the Dockerfile:
COPY mdb-sqlite.jar csv2json2.py select_point_to_point_links.sql /The Extract/Transform/Load Coordinator
I use Go to coordinate the pipeline, fetching, converting, and saving the data: fetch.go.
- I could have done the pipeline as a shellscript, but that's near-impossible to handle errors well, and wrapping inside an HTTP request/response handler is also difficult.
- Python would have worked, but I'm getting a bit over type errors in production, and deployment is harder than Go's static binaries.
- I'd had good experience with Go programs forcing good error-handling practices that make me more confident I can write Go code that'll keep working without admin overhead.
- Go has excellent libraries for interacting with Cloud APIs, fetching data over HTTP, and listening to HTTP requests.
My main function parses flags for what data to fetch, and where to cache the data, and sets up an HTTP server listening on the port that Cloud Run passes through the PORT environment variable.
var (
prismZipURL = flag.String("prism_zip_url", "https://www.rsm.govt.nz/assets/Uploads/documents/prism/prism.zip", "URL of zip to fetch")
bucketName = flag.String("bucket_name", "nz-wireless-map", "Google Cloud Storage bucket name")
)
func main() {
flag.Parse()
log.Print("Fetch server started.")
http.HandleFunc("/fetch", fetch)
port := os.Getenv("PORT")
if port == "" {
port = "8080"
}
log.Fatal(http.ListenAndServe(fmt.Sprintf(":%s", port), nil))
}Function fetch handles responding to HTTP requests: it's a simple wrapper around a fetchInternal that converts Go errors into HTTP 500 errors:
func fetch(w http.ResponseWriter, r *http.Request) {
if err := fetchInternal(r); err != nil {
w.WriteHeader(500)
log.Printf("%v", err)
fmt.Fprintf(w, "/fetch failed: %v", err)
return
}
log.Println("OK")
fmt.Fprint(w, "OK")
}I'm the only person who'll read these error messages, so I don't need to be too worried about leaking information through them. Cloud Run has an option to only allow authenticated requests to an API, so I don't need to worry about spam requests.
fetchInternal is a big long pipeline of code, which opens a connection to fetch the database.
func fetchInternal(r *http.Request) error {
resp, err := http.Get(*prismZipURL)
if err != nil {
return err
}
defer resp.Body.Close()
t, err := lastModifiedTime(resp)
if err != nil {
return err
}
...Before proceeding, we check the Last-Modified HTTP Response header, to see if the data has actually changed since last time:
client, err := storage.NewClient(ctx)
if err != nil {
return fmt.Errorf("Couldn't create storage client: %v", err)
}
tSuffix := t.Format(time.RFC3339)
bkt := client.Bucket(*bucketName)
blobJSON := bkt.Object("prism.json/" + tSuffix)
// Check if we've already created prism.json/{{timestamp}}.
// If we've already created this file, this means we can skip a bunch of work.
// This depends on the Last-Modified-Time in RSM's web server working, but
// it should work.
exists, err := objectExists(ctx, blobJSON)
if exists {
log.Printf("exiting early: we have already created %v, no need to redo", blobJSON.ObjectName())
return nil
}
Otherwise, we fetch the data into a byte buffer in-memory, and unzip with Go's excellent archive/zip standard library:
// Read in the response body: now that we've confirmed this is new data, we should load it in.
var zipTmp bytes.Buffer
n, err := io.Copy(&zipTmp, resp.Body)
if err != nil {
return err
}
zipR, err := zip.NewReader(bytes.NewReader(zipTmp.Bytes()), int64(zipTmp.Len()))
if err != nil {
return fmt.Errorf("error opening zip: %v", err)
}
prismMDB, err := findPrismMdb(zipR)
Looping over the files to pull out the Microsoft Access DB prism.mdb, it's refreshing to do this coding sometimes without using higher-order functions or queries. Go forces you to handle the error case:
func findPrismMdb(r *zip.Reader) (*zip.File, error) {
for _, f := range r.File {
if f.Name == "prism.mdb" {
return f, nil
}
}
return nil, errors.New("no prism.mdb found in prism.zip")
}
Shelling out to Java and SQLite is fairly simple in Go, as long as you're happy to handle errors. This runs Java code and then optimizes the output database using SQLite's analyze main call, without which the database is extremely slow to query.
func mdbToSqlite(mdbTmp *os.File, tmpSqlite *os.File) error {
// Convert to sqlite3
cmd := exec.Command("/usr/bin/java", "-jar", "mdb-sqlite.jar", mdbTmp.Name(), tmpSqlite.Name())
log.Printf("Converting to sqlite3: running %v\n", cmd.String())
if javaOutput, err := cmd.CombinedOutput(); err != nil {
return fmt.Errorf("couldn't read output from java: %v, output: %v", err, javaOutput)
}
// Analyze output with sqlite3
analyzeCmd := exec.Command("/usr/bin/sqlite3", tmpSqlite.Name(), "analyze main;")
log.Printf("Analyzing database in sqlite: running %v\n", analyzeCmd.String())
if analyzeOut, err := analyzeCmd.CombinedOutput(); err != nil {
return fmt.Errorf("couldn't analyze db: %v, output: %v", err, analyzeOut)
}
return nil
}
Querying the SQLite script is another shell out, capturing Stdout and Stderr into byte buffers. I really like how I can substitute in a byte buffer or a Cloud Storage filestream as an io.Writer.
func querySqliteToCSV(tmpSqlite *os.File, tmpCsv io.Writer) error {
// Run SQL to ouput CSV
sqlF, err := os.Open("select_point_to_point_links.sql")
if err != nil {
return err
}
var selectErr bytes.Buffer
c := exec.Command("/usr/bin/sqlite3", tmpSqlite.Name())
c.Stdin = sqlF
c.Stdout = tmpCsv
c.Stderr = &selectErr
log.Printf("Extracting data from sqlite: running %v\n", c.String())
if err := c.Run(); err != nil {
return fmt.Errorf("couldn't select: %v, stderr: %v", err, selectErr.String())
}
return nil
}
Converting CSV to JSON is much easier in Python than Go:
import sys, csv, json
json.dump(list(csv.DictReader(sys.stdin)), sys.stdout)Even if you count the overhead of shelling out to Python:
func csvToJSON(tmpCsv io.Reader, tmpJSON io.Writer) error {
var jsonErr bytes.Buffer
c := exec.Command("/usr/bin/python3", "csv2json2.py")
c.Stdout = tmpJSON
c.Stdin = tmpCsv
c.Stderr = &jsonErr
log.Printf("Converting to JSON: running %v\n", c.String())
if err := c.Run(); err != nil {
return fmt.Errorf("couldn't convert to json: %v, stderr: %v", err, jsonErr.String())
}
return nil
}
Finally, we write out the JSON to Google Cloud Storage, ensuring that the timestamped file is last to be written. The presence of the timestamped JSON file is a marker for successful run of the pipeline, suppressing future reprocessing of the same database, so it must be last.
I use different storage classes to reduce costs: more-expensive, faster STANDARD for data I'm querying directly over the web, and slower, cheaper NEARLINE storage for archival/rollback/debugging data.
// Save JSON to GCS
if err := writeToGCS(ctx, blobJSONLatest, bytes.NewReader(tmpJSON.Bytes()), "STANDARD"); err != nil {
return err
}
// Finally save to a timestamped JSON file. This is a history, as well as a
// way to tell if the pipeline completed end-to-end (above we check if this
// file exists to see if we can save work).
if err := writeToGCS(ctx, blobJSON, bytes.NewReader(tmpJSON.Bytes()), "NEARLINE"); err != nil {
return err
}
All source code is available on GitHub:
 mhansen
mhansen
Hooking up the Web UI
My first trouble was querying data in a Cloud Storage bucket: https://nz-wireless-map.storage.googleapis.com/prism.json/latest from a different domain: https://wirelessmap.markhansen.co.nz. The browser's same-origin policy prevents reading data on different domains, CORS pokes a hole in that.
I had to set up a Cross-Origin Resource Sharing config to allow NZ Wireless Map (at https://wirelessmap.markhansen.co.nz) to query data in Google Cloud Storage (on a different domain). cors.json lists an allowlist of origins that browsers will allow to read the JSON, and a list of headers the browser allows JavaScript to read.
[
{
"origin": [
"http://lvh.me:3000",
"http://localhost:3000",
"https://nzwirelessmap-firebase.firebaseapp.com",
"https://wirelessmap.markhansen.co.nz"
],
"responseHeader": [
"Content-Type"
],
"method": [
"GET",
"HEAD",
"DELETE"
],
"maxAgeSeconds": 3600
}
]After a lot of goosing around, I found you can set the CORS config for the Google Cloud Storage Bucket with the gsutil command line tool:
$ gsutil cors set cors.json gs://nz-wireless-mapFinally, in the NZ Wireless Map Web UI, I can grab the Last-Modified header of the JSON to get an approximate time the database was last updated, to show in the UI. This neatly sidesteps having to store the last-modified time in another database:
fetch("https://nz-wireless-map.storage.googleapis.com/prism.json/latest")
.then(res => {
this.setLastModifiedTime(new Date(res.headers.get('Last-Modified')!));
return res.json()
});Conclusion
It's been working pretty well over the last year. The cost is still under $1/month, even after storing a year's worth of archived databases, far better than the $10/month VPS I would otherwise be running this on.
I haven't had to touch it at all after setting it up, except to switch the nearline storage to save money. The service just keeps chugging on.
I would recommend Google Cloud Run and Google Cloud Scheduler for anyone who wants to run a multilingual fetch pipeline on a schedule and a low budget.



Comments ()