My 8-year Attempt to Automate NZ Wireless Map
This is part 1 of 2, part 2 is at: Automating NZ Wireless Map with Google Cloud Run.
Background: NZ Wireless Map
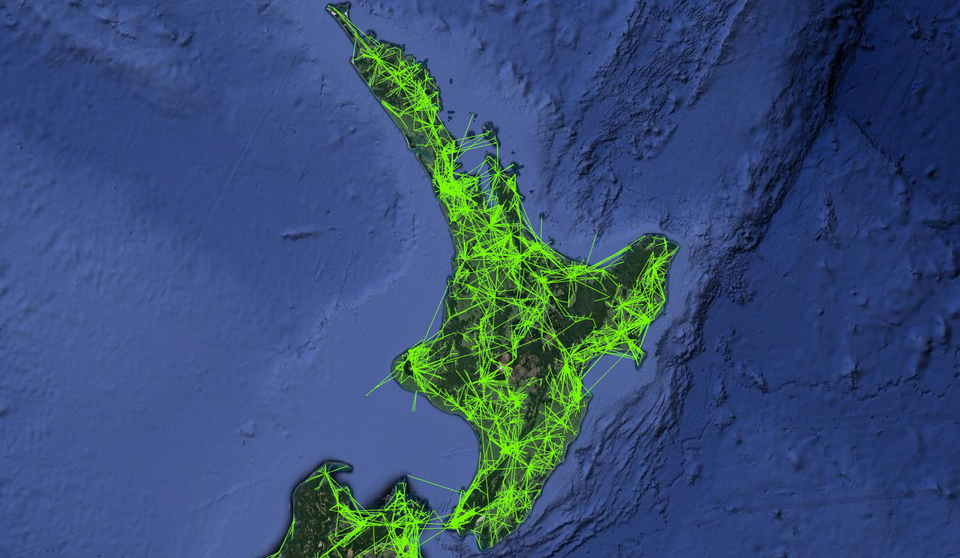
I run a website, NZ Wireless Map, which shows licensed wireless point-to-point links in New Zealand. The site is a visualization of government data, sourced from the Radio Spectrum Management authority.
I've run this site for over 8 years now - here's the announcement post from 2011.
This post is about the almost-decade-long process I went through trying, and failing, to automate updating the data shown on the map.
My main criteria:
- Low-maintennance: not a lot of time spent sysadminning. Solutions must be reliable.
- Cheap. This website is a hobby, and I don't make any money from it.
Disclaimer: I'm going to be talking a bunch about Google Cloud below, and I currently work at Google, and have worked on Google Cloud. These are my personal opinions.
How do you put an Access Database on the web?
TL;DR:
Radio Spectrum Management Website
(fetch)→ .zip file
(unzip)→ Microsoft Access Database
(convert)→ SQLite Database
(run sql)→ CSV wireless links
(convert)→ JSON wireless links
(upload)→ NZ Wireless Map
Radio Spectrum Management kindly provides the data in Microsoft Access 2000 format. It's prism.zip (42.3 MB), which contains prism.mdb (306MB), the Microsoft Access database.
It's about 16 tables, with somewhat complex foreign key relationships, so Microsoft Access is not an unreasonable choice. Radio Spectrum Management also ship a Windows application that can read this database.
I don't have a Microsoft Access license handy, so I convert the file into sqlite3 format using the now-archived, but still-working mdb-sqlite project:
$ java -jar mdb-sqlite.jar prism.mdb prism.sqlite3
Then I run a query over the data using sqlite3, which does a bunch of joins and outputs the data in CSV format:
$ cat point_to_point_links.sql | sqlite3 prism.sqlite3 > prism.csv
Finally, I convert the CSV format to JSON, with a short csv2json.py Python program:
import sys, csv, json
json.dump(list(csv.DictReader(sys.stdin)), sys.stdout)
This finally outputs the prism.json file I can use in on the website.
I also have a Ruby Rakefile, like a Makefile, which plumbs these tools together.
Data Licensing
Radio Spectrum Management's data is Crown Copyright, with a license, provided you follow these rules (emphasis mine):
The information provided on this website may be reproduced for personal or in-house use free of charge without further permission, subject to the following conditions:
- you must reproduce the material accurately, using the most recent version
- you must not use the material in a manner that is offensive, deceptive or misleading
- you must acknowledge the source and copyright status of the material.
These terms are very reasonable. Unfortunately, I had fallen a bit short of this license, updating the site only once every few months, because the process was so manual. In practice, users of the site would email me to ask for an update, and I'd run the pipeline on my laptop.
This wasn't ideal, so over the years I wondered about how I might automate this.
Previous Automation Attempts
2011: Google App Engine
I was hosting NZ Wireless Map on App Engine, and at work, I was running production Google sites in Go on App Engine. It was a great experience, so why not try to automate the fetching and data conversion in App Engine too?
App Engine was great:
- auto-scaling, spin up as many or as few instances as you need
- generous free tier
- pay for the seconds you use
- auto-scale down to nothing
- cron service included
- blob storage included
App Engine was years ahead of it's time. Serverless and Lambda and Functions-as-a-Service are huge buzzwords today, but we were doing similar things with App Engine in 2011.
But App Engine had a rigid sandboxing model: you had to send your code to Google for compilation, and native code was disallowed. No C-extensions in Python, or Go, or Java. And your app all had to be written in one language: Go, Python, or Java.
Alas, in my pipeline to convert the data, there were many different types of technology, and languages:
mdb-sqlite: Javasqlite3: Ccsv2json: Python
The presence of sqlite3, a C extension, ruled out being able to run on App Engine.
It's a shame about App Engine's sandboxing model, I think it could have seen much more uptake if it was a little more flexible.
2011: Virtual Machines
Virtual Machines are very flexible: you can run whatever language you want. In the early days of Cloud, everyone was using them for everything.
But they're also expensive: you typically keep them on all the time. You don't just spin them up once a day to run a task.
And they're high-maintennance: if you're hosting them on the internet, you need to patch them all the time, applying updates to the kernel, and it's large surface area. I just don't have the time to sysadmin that.
2016: AWS Lambda, Google Cloud Functions
In 2014, AWS Lambda shipped, and blew up the tech world. Sometime later, I took a look at it, alongside the similar Google Cloud Functions.
This felt really similar to Google App Engine: you upload your code (as a .zip file of JavaScript, the only supported language at the time!), and the Cloud spins up and down servers as requests come in, and you're only charged what you use.
I was looking for a way to run sqlite3 and Java in a Lambda, but while there were a few hacks that seemed to tunnel Java+C code into a mostly JavaScript runtime, none of them seemed particularly legit. Overall, it seemed like a regression from App Engine: JavaScript, with it's myriad of error-handling methods (exceptions, error returns, Promise catch), is just really hard to write reliable automation in.
So I gave up on these Functions-as-a-Service offerings.
2018: Google Kubernetes Engine
Kubernetes was apparently like Google's "Borg" Cluster Scheduler, but open-source, and in 2018 it was blowing up the tech world.
In my day job, I was working on Google Cloud Platform, so I thought I'd kick the wheels on Google Kubernetes Engine. It seemed to offer a few things I wanted:
- CronJobs
- running Docker containers, containing code written in multiple languages
I was hoping this would be similar to Borg+Borgcron at work, where you specify a container, and the infrastructure takes care of job placement and kernel updates, and you pay by the second. But Google Kubernetes Engine was really just a way to manage running Kubernetes on three virtual machines, and you still had to manually update the version of Kubernetes running on the cluster.
A cluster of three machines was total overkill, and far too expensive for this hobby website. And the sysadmin effort would still be too high. So I gave up on Google Kubernetes Engine.
To Be Continued
My next post, Automating NZ Wireless Map with Google Cloud Run, describes how I finally succeeded, automating the data updating, using Google Cloud Run. Cloud Run lets you run a docker container on a fully managed environment, charged by-the-second. Like App Engine but letting you run any language. I'm a huge fan.



Comments ()