Cloud Backup Software

After my last blogpost, where one of my hard drives was maybe taken out by lightning, I was reminded to reevaluate my backup strategy.
I have data on my macbook, and on my Synology NAS. My macbook's backups are all good, having revisioned daily backups on Arq.
But my big files that live only on the Synology NAS (mostly disk images taken from disks inherited from a deceased estate) were only "synced" to Google Cloud Storage, by Synology Cloud Sync. Cloud Sync is not revisioned – only the latest version is kept, so a corrupted source would overwrite the sync. So, not really backups! Time to re-evaluate cloud backup software. I'm looking for software that will run on the NAS (Linux, Synology), at a reasonable cost for 1TB of backups, client-side encrypted, maybe with a year's worth of version retention.
Spoiler: Ultimately, I use Arq to backup my Macs, and Duplicacy for my Synology Network-Attached-Storage (NAS) device. See below.
Arq: It's OK
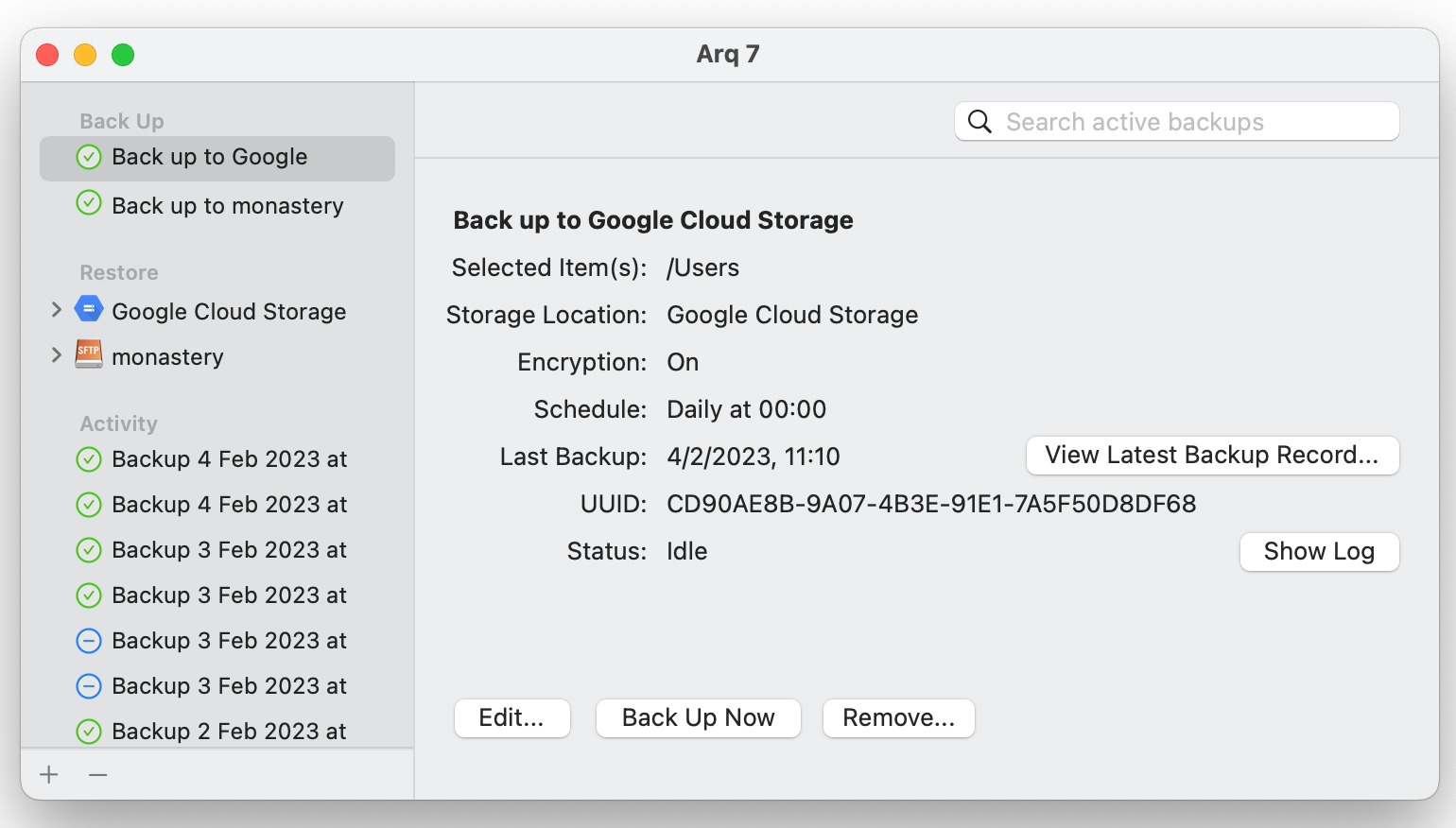
Arq is decent, and I use it for my Macbook. It uses a modern, content-addressed storage format. It mostly works, although I do worry when I hear about the developer breaking backwards compatibility between versions. And the UX is a little awkward to find things. And I worry a little that it's closed-source, but I'm reassured by them documenting the storage format. Overall, I would weakly recommend it as the best of a bad bunch.
But Arq doesn't run on Linux. So I can't use it on the Synology.
Crashplan: The Good Old Days
Crashplan used to be good. I used to use it. The price point was great and the software mostly just worked. But then they shut down their consumer offering, leaving only a too-expensive small business offering. A real shame.
Backblaze: The Market Leader
Backblaze is the best left after Crashplan exited. It's the Wirecutter recommendation. But I don't like Backblaze's software offering:
- Backblaze has no option to 'restore in place'. Your only restore options are downloading the data as .zip from a web UI, or requesting a delivery of a disk. Why not? All the other backup software offers in-place restores. Is it the challenge of a 3-way merge? Data is more than just the bytes; it's the metadata, the permissions, this is just not captured in the archives you download from the web. A dedicated restore software could do this. I don't know why they don't. Update, Aug 2023: Backblaze have announced a "new local restore experience". Good!
- By default, Backblaze will only keep 30 days of data. If it takes you longer than a month to notice data corruption, sorry! You're screwed. This is, frankly, a bonkers default to have. To their credit, they now allow longer retention (1 year for +$2/month, or pay-per-GB for >1yr). Update, Aug 2023: Backblaze raised prices by $2 and announced "all Computer Backup licenses may add One Year Extended Version History, previously a $2 per month expense, for free".
- When I last used Backblaze a few years ago, they immediately started uploading my backups in plaintext, before I had a chance to say "no, I want mine encrypted". While this probably makes their software easier for unsophisticated users (some growth hacker probably got promoted for it), it's a breach of trust to hoover up my personal files when I want them encrypted. I have no idea if they've fixed this now.
With these limitations, Backblaze being Wirecutter's annointed 'best' is an indictment of the backup software industry.
Synology Hyper Backup: Slow
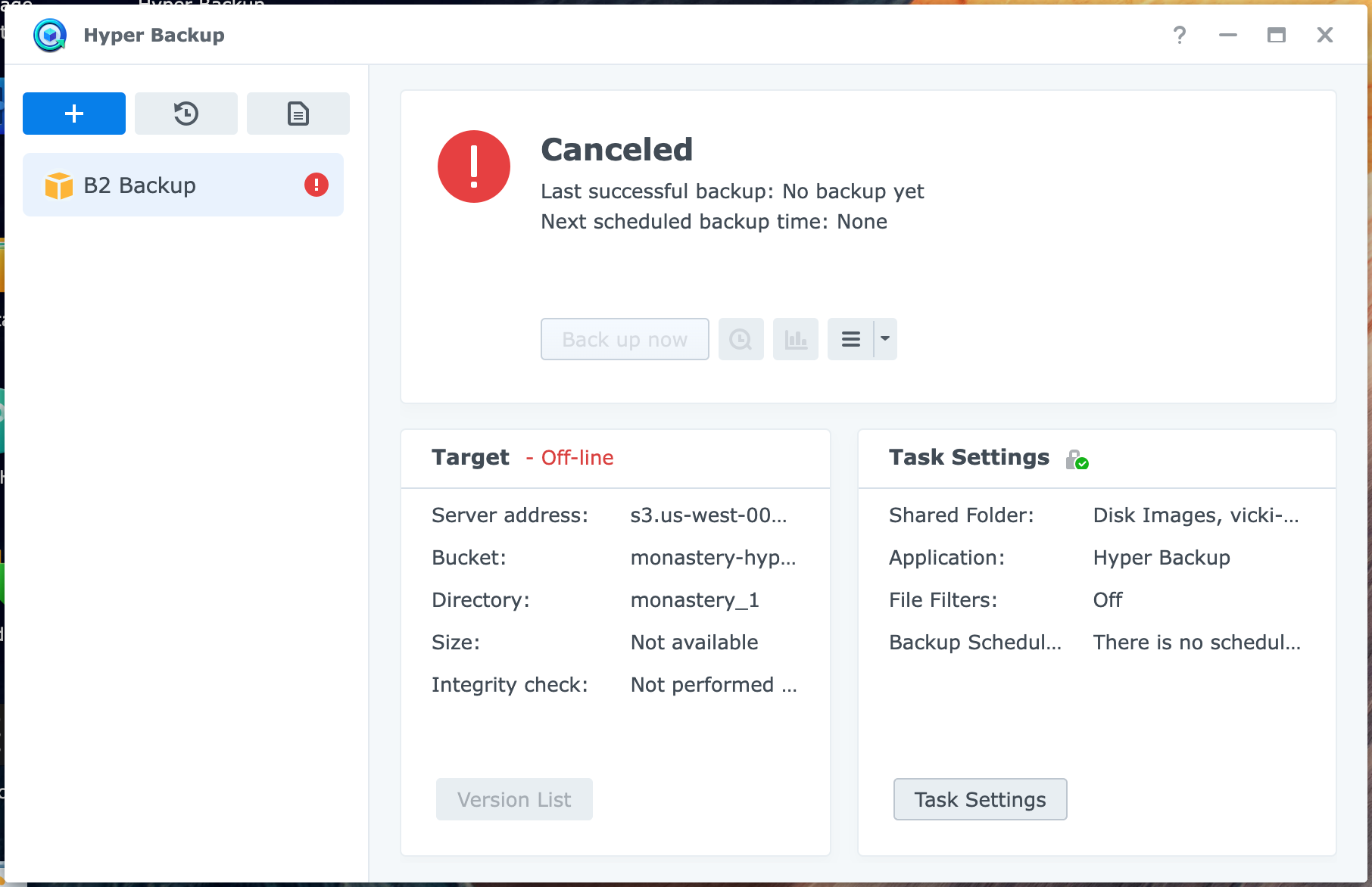
I thought, Synology's built-in backup software will probably be decent, right? Commercial company behind it that sells lots of data backup boxes, hopefully they put some effort into this? A lot of people on /r/synology recommended it.
In positives, it's well-integrated with Synology, with emails alerts on failure, and can backup Synology software configuration. It has compression, and scheduling. It has an active user base. And it's built-in.
But unfortunately, I was disappointed, and gave up on Hyper Backup.
Synology Hyper Backup's Format is Secret
Having a secret data format is, I think, such an own-goal for backup software. It helps trust so much to be able to say "it doesn't matter if we disappear, here's how to read the data". You have to document it anyway for your own engineers, just make the docs public!
The closest we get to an explanation of the data format is this bullet-point-heavy marketing page.
To their credit, Synology have a software package that can read the backup files, Synology Hyper Backup Explorer, but this is still cold comfort if the backups get corrupted, as some people report happening in forums.
Synology Hyper Backup is Slow
It's extremely slow. Here's a representative progress bar: 0.00 B/s. It would jump between 0 and 1MB/s, mostly staying on 0.
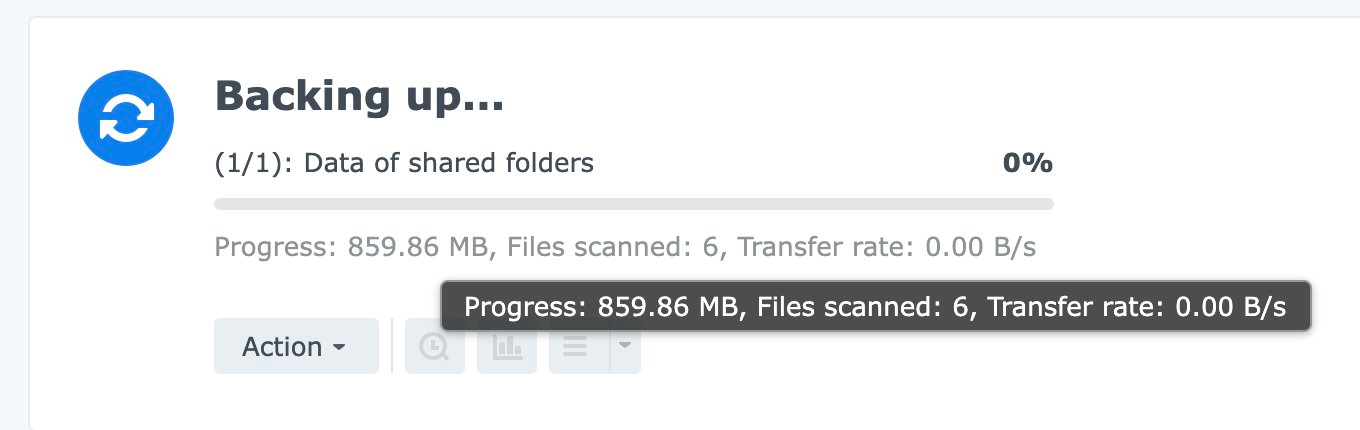
I don't know why it was so slow. If you google [synology hyper backup slow], as you might expect, there's a lot of laypeople on the forum confidently being wrong about what makes it slow. Compression? Network bandwidth? Disk I/O are all given as explanations. Let's consider these.
Many people say compression will slow down the backup. I had compression enabled. But compression is usually very fast, and CPU-bound, and the CPU stayed at <10%. Even if it was 'nice'd, you'd expect it to be able to burst to use idle CPU. So we can immediately discount compression as a cause.
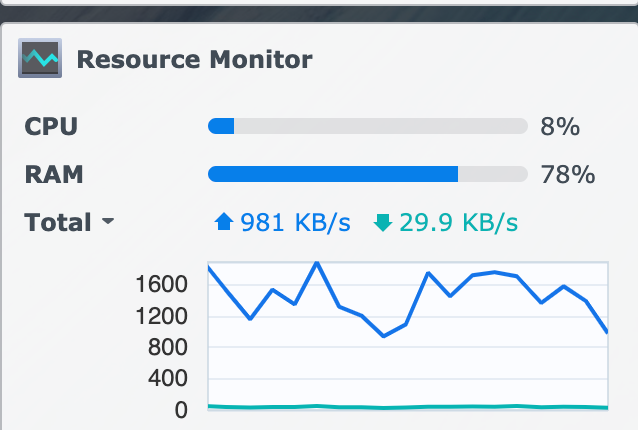
And htop confirms, the HyperBackup jobs are using 0-1% CPU.

My hard drive can read at 10MB/s, if sequential. Seeks will reduce this, but not to zero.
And my home internet upload pipe is 40Mbps (or about 4MB/s, after overhead). And I can regularly hit that 40Mbps, whenever Synology Cloud Sync runs.
So I wonder, what the heck is Synology Hyper Backup doing? I don't have the linux-perf-tools profiler installed, but I have "poor man's perf", looking at the kernel stack of the threads: cat /proc/$pid/stack. First I find the pid using pstree, with -p to show pids, we see that synobackupd is the root job, spawning img_backup which spawns img_worker which spawns img_backup and php.
You could expect the leaf nodes to be doing work, but here the img_backup tool is sleeping, calling the nanosleep system call. I can't tell exactly how long it's sleeping for (though I tried), but I'm guessing it's a long time, and that that's probably why my backup is slow.
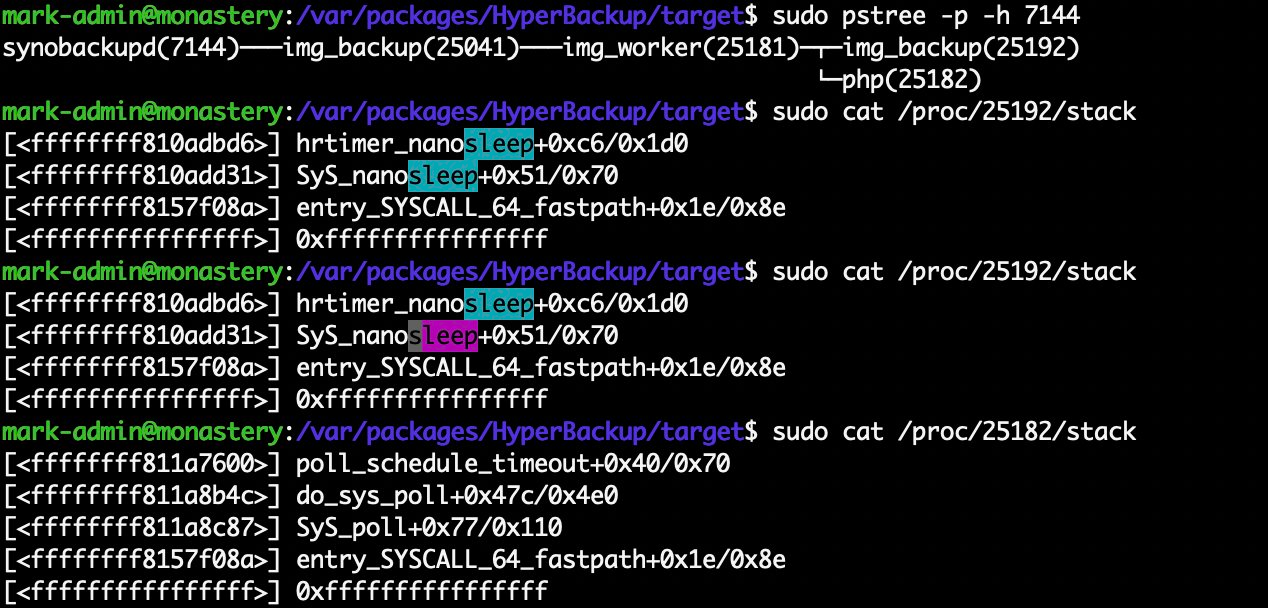
The PHP process is at least polling a file descriptor for work to do, rather than sleeping. I looked at the PHP source – it's the plugin for uploading to S3. I found about 400 lines of uncommented PHP.
It seemed kind of a bizarre choice to use PHP as a backup software adapter. AWS S3 has bindings for all languages. Is it language-chauvinist to say it didn't inspire confidence? Well, backup software is all about trust, and uncommented PHP doesn't inspire trust.
Between the slowness (it would have taken weeks to upload), the lack of transparency into what it's doing, and the closed-sourceness, I wasn't keen. So I looked into other stuff.
Duplicity: Obsolete
Duplicity bills itself as "encrypted bandwidth-efficient backup using the rsync algorithm". It's webpage quaintly declares a "A standards (CSS) compliant web browser will display this page correctly". It's command-line, it's mature.
It's format is open: full backups are tarballs, and incremental backups are tarfiles containing new files and diffs. It relies on librsync to find diffs.
Managing full and incremental backups are a pain. Long incremental chains make it slow to recover data, and prevent garbage-collection of any file in the full backup (costing you extra storage).
To work around this, their advice is:
Keep the number of incrementals for a maximum of one month, then do a full backup.
But if I want a year's worth of backups, this means I'm redundantly storing 12x my dataset. That's going to cost me real money.
And rsync is fast if you have ssh access to the remote to run a rolling checksum there, but not so fast with modern cloud object storage where you don't have that. I'm not sure exactly if Duplicity downloads the full blob, but it certainly has to download the checksum header in the tar file. And with cloud object storage, that'll cost you exorbitant egress fees.
The full/incremental backup strategy is obsolete in 2023. Really, I'd argue it's been obsolete ever since Git popularised content-addressable-storage and immutable data structures plus garbage collection.
Duplicati: Unmaintained?
Duplicati is "Free backup software to store encrypted backups online". It's open source, written in C#, with a nice web interface. It looks really nice!
The system is completely open-source, even the web UI. C# is a language that inspires confidence. And the data format is modern, playing well with cloud object storage: garbage-collected content-addressed chunk storage.
But the last commit was merged over 6 months ago. It sounds like the maintainer doesn't have time, and there are insufficient volunteers. While I could volunteer, I already have open source commitments. I'd like a backup software that's actively developed, if only to get security fixes.
Duplicacy: Good enough?
There are too many backup tools that start with "Dupli-". It's very confusing.
Duplicacy says it "backs up your files to many cloud storages with client-side encryption and the highest level of deduplication". It's open-core, with an open-source free-for-personal-use command line tool, and a paid web UI to manage it. It's written in Go, which is probably the language that inspires the most confidence for me (they're probably not ignoring errors!).
The data format is very modern: content-addressed chunks. Just like Git. There's no need to read the chunk content back from the cloud to see what's inside it. And they have a clever two-step garbage collection process, which was neat enough that they got an IEEE Transactions on Cloud Computing paper out of it.
Duplicacy was able to max out my upload bandwidth. There's a way to install it on Synology. There are things I'm worried about: I was able to wedge the web UI behind a lock on first use, and leak goroutines (bug report), the developer has limited time between this and other projects, and email alerting seems limited or unimplemented. But it's seeing regular development (MR merged 2 weeks ago) and releases (last Dec 2022).
I'm impressed with the data format, and the open core means I'll be able to recover or move my data easily even if I don't pay for the web UI.
Duplicacy is the winner, for now. I forked out the money for a personal license for the web UI.
Software I haven't looked into
- Borg Backup looks like it has a modern data format, and is seeing active development. Although it doesn't natively back up to cloud, so would double my local disk space.
- Restic backup was recommended by a few people, and seems to see active development.
- Kopia backup is open-source, backs up to clouds, deduplicates, and has a GUI. Looks like a good option, but I found out about it too late.
Conclusion
If you're on a Mac or Windows, I recommend Arq. I don't recommend Backblaze.
If you're on Synology, I recommend Duplicacy. I don't recommend Synology Hyper Backup. Duplicity is obsolete. Duplicati's development has stalled.
All backup software has tradeoffs and bugs. I don't feel great about anything I've tried, really. I wonder if backup software is a Market for Lemons, where most people don't have to restore, and so they don't even know if their backups work, and the market sinks to dodgy players. That's another post, though.
Next in this series: What location should I backup to? I evaluate where cloud backup storage providers, and how to setup Duplicacy email notifications with Mailgun.
Reddit discussion of this post.


Comments ()